Luego de tener la sorpresa de que nuestro servidor de base de datos (dedicado solo a esa tarea) dejara de funcionar por falta de espacio en disco, tuvimos que iniciar una proceso de auditoría para determinar si las causas eran por uso normal o por alguna situación anormal en su funcionamiento.
Luego de tener la sorpresa de que nuestro servidor de base de datos (dedicado solo a esa tarea) dejara de funcionar por falta de espacio en disco, tuvimos que iniciar una proceso de auditoría para determinar si las causas eran por uso normal o por alguna situación anormal en su funcionamiento.Tenía un vago recuerdo que hace unos años atrás la base de datos no superaba los 500 Megas para almacenar los datos en disco. En GNU/Linux los datos se encuentran ubicados en el directorio /var/lib/pgsql/data y con solo hacer un du -h --max-depth=1 sobre el directorio nos mostrará el "uso de disco".
Lo malo de estos casos es que este tipo de situaciones se pueden prever si se cuenta con un Administrador de Bases de Datos (DBA), pero cuando estás en una situación que careces de él, debes repartir tu trabajo diario de desarrollador por el de "DBA Part Time" (con todos los riesgos que conlleva).
Mi sorpresa fue mayúscula al enterarme que a principios de febrero la base estaba consumiendo en el entorno de los 6 Gigas de disco. Luego de seguir su evolución por varios días pude concluir que el crecimiento rondaba los 100 Megas diarios, lo que parecía exagerado teniendo en cuenta la cantidad y el tipo de información que se ingresa por día: generalmente datos "planos", no existiendo ingreso de información "binaria", es decir, documentos, imágenes, etc.
LVM: Logical Volume Management
Primer medida de contención que tuve que tomar fue la de separar en distintas particiones determinadas zonas críticas de consumo de espacio de disco: zona de datos, zona de logs y zona de respaldos (si, es algo que se debe de planear antes, pero así ocurrió por la falta de tiempo y el apuro de cumplir con otras tareas).
Lo que mejor se me ocurrió fue implementar el famoso LVM: Logical Volume Management (Administración de Volúmenes Lógicos).
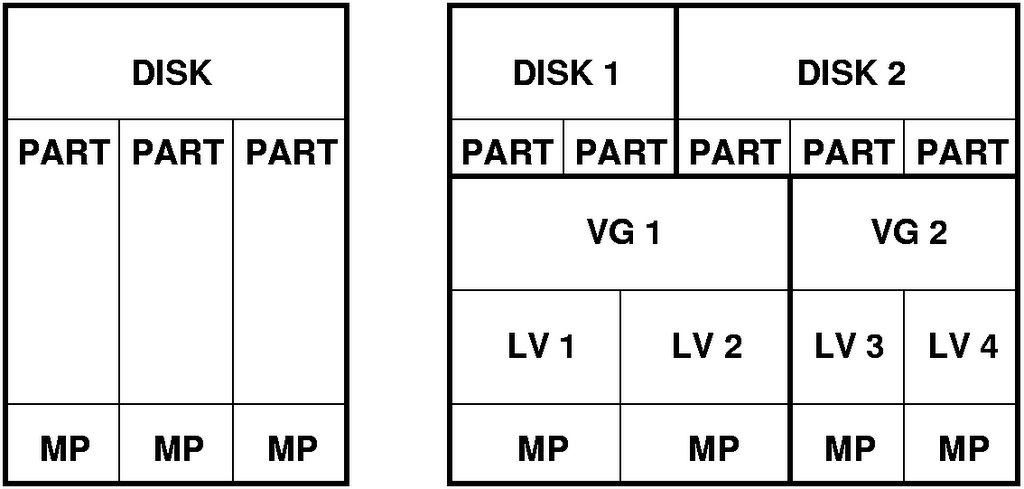
Esta utilidad no es novedad del ambiente GNU/Linux, en sí muchos sistemas Unix de nivel empresarial ya manejan desde hace mucho tiempo antes este concepto: la idea es contar con una partición física y crear dentro varios volúmenes lógicos, a los cuales les podemos asignar dinámicamente su tamaño.
Lo bueno de esta técnica es que nos permite administrar el espacio a nuestro gusto como si fuera una partición común, pero adaptable según nuestra necesidad, sin tener que estar obligados a crear nuevas particiones, darles formato, mover los datos a la nueva partición, tener el servidor fuera de funcionamiento por un tiempo, etc.

Obviamente, siempre y cuando tengamos un buen margen de espacio libre para poder asignar y desasignar de nuestros volúmenes lógicos.
El mantenimiento de la base de datos
Esta base de datos necesita un determinado "mantenimiento" (en sí, todas lo necesitan) que es provisto en general por una utilidad propia de este motor que se llama vacuum.
En nuestro caso disponemos de una tarea planificada que corre a primera hora de la mañana y a última hora de la noche. Esta aplicación efectuaría el mantenimiento estándar de la base de datos, que comprende (según el siguiente FAQ):
"Para determinar si debe ser usado un indice, PostgreSQL debe tener estadísticas acerca de la tabla. Estas estadísticas son obtenidas usando el comando VACUUM ANALYZE, o simplemente ANALYZE. Utilizando las estadísticas, el optimizador sabe cuantos registros hay en la tabla y de esta manera puede determinar mejor si los índices deben ser usados. Las estadísticas también son valiosas en el momento de determinar el orden de unión o el método de unión óptimos. La obtención de estadísticas debe ser realizada periódicamente conforme los contenidos de las tablas cambien."
¿Qué significa esto? Que debemos programar que corra este utilitario regularmente para hacer este mantenimiento en las horas que se supone no afecten el desempeño de la base de datos.
En nuestro caso usamos un pequeño scripts que tiene la siguiente sintaxis:
time su - postgres -c "vacuum --all --verbose --analyze"
Pero a pesar de todo, este "mantenimiento" se viene haciendo diariamente desde que tenemos la base de datos en producción... entonces, porqué sigue creciendo exponencialmente?
Cuando todo falla, hay que leer los manuales
La base de datos siguió aumentando de tamaño con los días, pero ahora a 200 megas por día. En los últimos días la base de datos había crecido de 6 Gigas a 9 Gigas, y que gracias al LVM se pudo contener al reasignar espacio libre de otras particiones.
Luego de releer nuevamente todos los manuales de las aplicaciones involucradas, el siguiente apartado vuelve a tener sentido para mi:
--fullPor los comentarios que estuve leyendo en grupos de discusión, muchos administradores aconsejaban este procedimiento cuando hay mucho ingreso y borrado de información, o cuando se crean o borran abruptamente tablas o bases enteras. El tema era que desde que estamos usando Postgres en producción, nunca usamos la opción "full", solo la alternativa "estándar" (y así lo recomiendan los manuales). La opción vacuum que estábamos usando hace un "bloqueo" a nivel de tuplas para correr el proceso de mantenimiento, y la diferencia con la versión "full" es que el proceso es mucho más profundo y el bloqueo es a nivel de tablas, no siendo posible correrlo en horarios de trabajo de la base de datos.
"Selects "full" vacuum, which may reclaim more space, but takes much longer and exclusively locks the table."
Actualmente a los scripts de mantenimiento le agregamos el "--full", y la situación cambió radicalmente.
Estos se ejecutan todos los días, 7:30am y 21:30 pm, unas horas antes del uso intensivo de la base de datos. La idea de la primer hora es que la base de datos se encuentre pronta justo antes de la hora crítica de trabajo, y la hora nocturna para adelantar el trabajo de la primer hora (la degradación de la base es acumulativa, por decirlo de alguna manera).
Comentario al margen: de todas formas no sería tan necesario hacer este proceso todos los días, se podría hacer una vez por semana o por mes, según evolucione el uso de la base y el consumo de espacio.
Resultado Final
Bueno, la primera vez que corrió demoro 1 hora y media, y cuando me enteré del resultado final casi me da un infarto: ¡de 9.2 Gigas pasamos a 700 y poco megas! ;-)
Mi primera impresión fue: "¡listo, lo que me faltaba, acabo de destruir la base de datos!" ;-), aunque el comentario proviene de alguien que es normalmente histérico con su trabajo, pues los respaldos estaban al día, y antes de hacer todos estos cambios se hicieron más respaldos adicionales, previendo tener que rearmar la base desde el respaldo (de todas formas, el cambio fue demasiado impactante ;-).
Luego de verificar que los datos eran coherentes, que la base funcionaba, que los logs no reportaban errores, etc, la última evaluación terminó de serenarme: los respaldos posteriores a esta "depuración" tenían el mismo tamaño que los respaldos anteriores. Esto significa que si tomamos en cuenta que el respaldo a través de un dump concluye con un archivo de texto con todas las sentencias sql para rearmar la estructura de las bases existentes, tablas y datos, el hecho que ambos respaldos tuvieran el mismo tamaño garantizaba que los datos eran los mismos (o por lo menos, que era la misma cantidad de información) y que no se habían perdido datos.
Conclusión
Primero, antes de hacer todo esto, _siempre_ debemos estar al día con los respaldos, tenerlos probados que funcionan (auditorías regulares) y que recuperan toda la base de datos sin faltar nada (es el 50% del respaldo tener verificado que funciona). Segundo, no olvidar del mantenimiento de Postgres, y tercero, siempre, "cuando todo falle, lee el manual", aunque sepas que alguna vez lo leíste de arriba a abajo ;-)
Ejemplo de configuración de un mantenimiento regular
En el crontab se podría agendar para que lo haga en horas que no se esté usando la base de datos:
30 7 * * 1-5 /var/respaldos/scripts/mantenimiento_postgresql.sh
30 21 * * 1-5 /var/respaldos/scripts/mantenimiento_postgresql.sh #!/bin/bash
ECHO=`which echo`
TIME=`which time`
SU=`which su`
VACUUM=`which vacuumdb`
$ECHO "Mantenimiento Base de Datos"
$TIME $SU - postgres -c "$VACUUM --all --full --verbose --analyze"
PD: no, no, y no, no me gusta el trabajo de "DBA Part Time" ;-)
Documentación
PostgreSQL
LVM
Actualizaciones
- 7/2/2007 - Scripts de respaldos y configuración del crontab.